Wielocechowa analiza statystyczna dla próby z populacji polskiej
- Szczegóły
- Kategoria: Wielocechowa analiza statystyczna
Badana próbka to 50 osobników określonych taksonomicznie przez Michalskiego na konferencji typologicznej w 1953 i 1955. Do klasyfikacji użyto wskaźników (główny, morfologiczny twarzy, twarzy górnej, nosa), wzrostu, profilu nosa, koloru oczu, włosów i skóry. Jako dane pomocnicze wykorzystano ukształtowanie powieki górnej, wystawanie kości policzkowych i kształt włosów (dwóch ostatnich nie uwzględniłem w analizie).
Arkusz z danymi do pobrania (dane nieustandaryzowane + plus ich opis i wyjaśnienie skal)
Arkusz z danymi ustandaryzowanymi
Ja dodałem do analizy dla większego zróżnicowania wymiary bezwzględne w mm (długość i szerokość głowy, wysokość twarzy górnej i całkowitej, szerokość twarzy, wysokość i szerokość nosa). Na ich bazie obliczyłem wskaźniki jarzmowo-ciemieniowy,wysokości nosa oraz wskaźnik wysokości górnej wargi (osiągał najwyższe wartości w grupie o przewadze elementu L oraz w typie Eq, więc na pewno miało sens jego dodanie).
Aby analiza była jeszcze bardziej dokładna i neutralna, wykorzystałem skale liczbowe Michalskiego stworzone dla poszczególnych stopni skal kolorów włosów (tutaj), kolorów oczu (tutaj), profilu nosa (tutaj), oraz ukształtowania powieki górnej (tutaj) i koloru skóry (tutaj). Po przeliczeniu na skale liczbowe również dla nich obliczyłem odchylenia standardowe.
Dane brałem dla wskaźników i cech z kart poszczególnych osobników, z albumu dołączonego do PA [1955]. Wymiary zaś z tabeli zamieszczonej w PA [1953] na s. 219. Trzy pozostałe wskaźniki obliczyłem automatycznie w arkuszu kalkulacyjnym.
Wszystkie cechy "ważą" po standaryzacji tyle samo i jest ich 20 w maksymalnym dendrogramie. Nie jest faworyzowany wskaźnik główny, ani pigmentacja. Wynik analizy zaś jest bardzo ciekawy. Wynik grupowania przedstawiam na wygenerowanych kilku dendrogramach segregujących wg różnych algorytmów i metod obliczania odległości.
Najpierw wyjaśnienie czemu niektórzy AE i YE mają w nawiasach przeciwne oznaczenia. Chodzi o to że w artykule z 1953 było tylko dwóch YE (nr 18 i 31). Z kolei w 1955, na stronie 661 mamy zaliczonych do YE, czterech dodatkowych, poprzednio będących AE. Tych których uznałem że prawidłowo to YE (AE). Poza tym znajdują się z reguły w jednej grupie z "pierwotnymi" YE. Ci którzy wg mnie powinni zostać w pierwotnym oznaczeniu to AE (YE).
Dodatkowo element B właśnie pod względem wskaźników jest nieodróżnialny od Y, wiec program potraktował je tak samo, gdyż nie wie o ciemnej pigmentacji i niskim wzroście czystego typu berberyjskiego B :).
Analiza głównych składowych (PCA)
z podkreśleniem różnic mędzygrupowych

Detrended Corespondence Analysis (DCA)

Dendrogramy
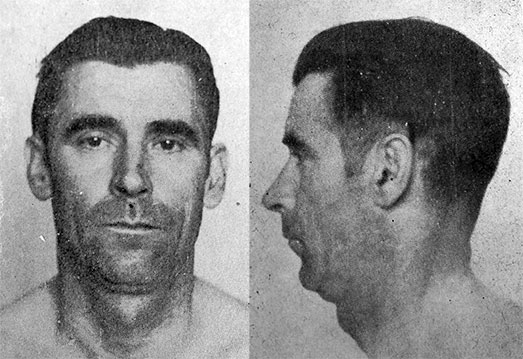
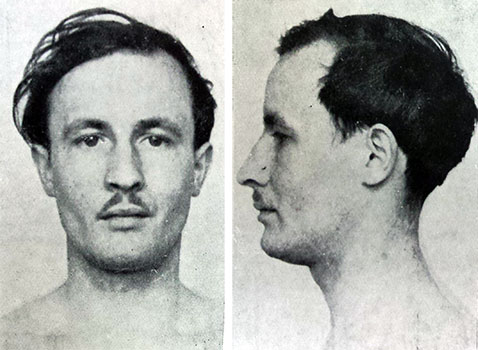
Na początek banalny przykład z typowym zestawem 5 cech (wskaźniki główny, twarzy całkowity, nosowy oraz kolor oczu i włosów) używanym w polskiej taksonomii (Czekanowski, Wanke). Wydzieliło typy i niektóre ich frakcje (szczególnie typu AL i AE) niemal idealnie. Jedynie połączenie nordyka aA 15 z parą YE budzi wątpliwości. Osobnicy należący do typów rzadkich w badanej próbie, jak np. EQ, YL czy AB będą w tych dendrogramach często dołączani do innych zbliżonych typów, po prostu program musi gdzieś ich "sparować" ale nie są to przyporządkowania przypadkowe jak sprawdzić ich cechy. Jak np. widzimy pojedynczy HH, Hl AH i jeden z YH zostali włączeni w jedną grupę "armenoidalną". Tak samo grupa "laponoidalna" zawiera w sobie dwóch YL, pojedynczego reprezentanta frakcji laponoidalnej aL oraz dwóch laponoidalnych hL. Wracając do Eq 3, będzie w dendrogramach korelował często z aE 19 bo poza jego prognatyzmem mają bardzo podobne wymiary i cechy, a nawet są fizjonomicznie dość podobni wg mnie (patrz zdjęcie Eq 3 oraz aE 19). Jakbym zrobił tylko dla EQ skale prognatyzmu (wszyscy inni mieli by 0 np.) to by oczywiście go wyrzuciło zapewne gdzieś na bok, ale szkoda czasu. Zresztą to tez może być wspólny element E przecież.
Użyto metody nieważonych średnich połączeń (UPGMA) w oparciu o miarę podobieństwa euklidesową.
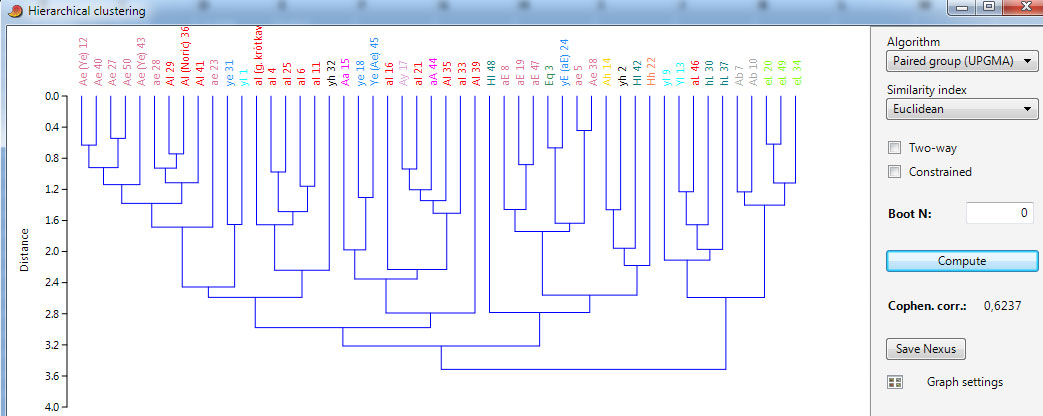
Kolejny przykład z dodanym wzrostem używany najcześciej w taksonomiach zagranicznych. Układ jest prawidłowy - grupy pokrewnych typów (czyli ze wspólnym jednym elementem np. YL i YE), pojedyncze typy oraz ich niektóre frakcje zostały wydzielone z bardzo dużą precyzją. Nordycy kojarzą się zaś zależnie od frakcji z typem AE lub AL co jest logiczne.
Użyto metody nieważonych średnich połączeń (UPGMA) w oparciu o miarę podobieństwa euklidesową.
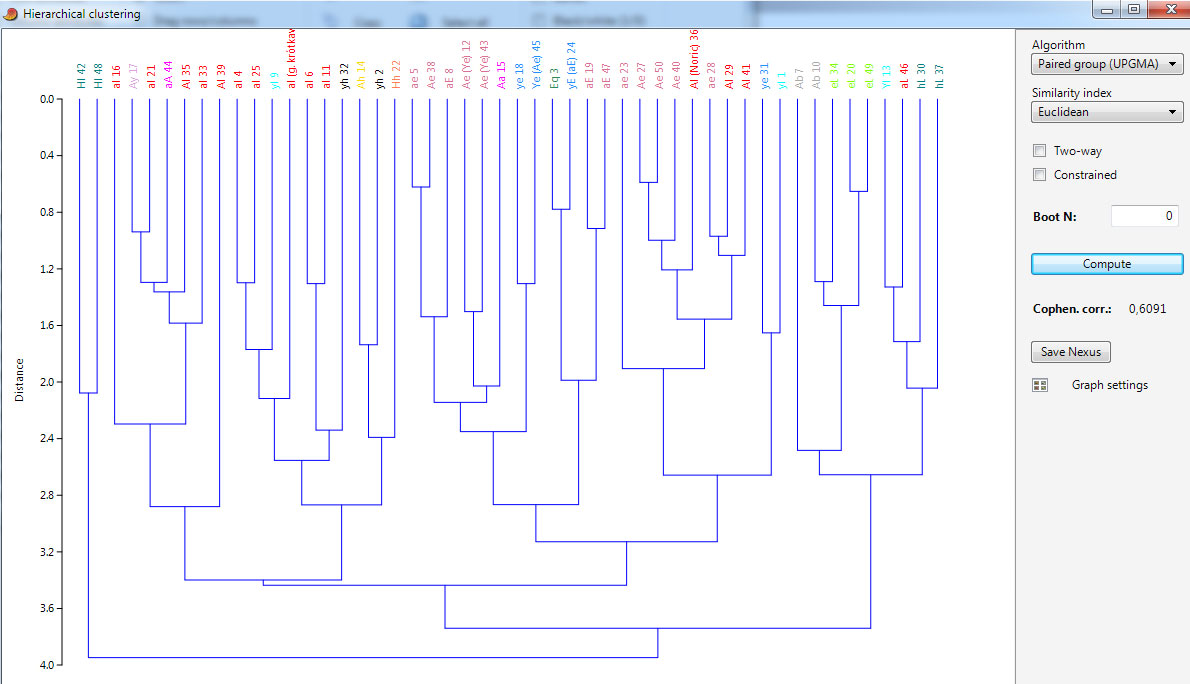
Teraz dodamy cechy brane pod uwagę przez Michalskiego w jego określaniu taksonomicznym (profil nosa, fałda powiekowa; kolor skóry).
Widać że jedyny czysty typ elementarny nordyczny został wydzielony (AA). Lepiej pokazało też typ HL (oprócz Hl 48). Zgrupowanie w jednej grupie pary armenoidalnej (HH i AH) oraz AE 8 (zdjęcie) i AE 38 (zdjęcie) na pierwszy rzut oka w dziwnej korelacji ma sens. Bo ta grupa poza wsk. głównym ma dość podobne wymiary oraz cechy (np garbaty nos) i jest zapewne wykrzyżowana z typy dynarskiego AH (facja dynarska / armenoidalna).
Użyto dla odmiany metody nieważonych średnich połączeń (UPGMA) w oparciu o miarę podobieństwa Dice'a
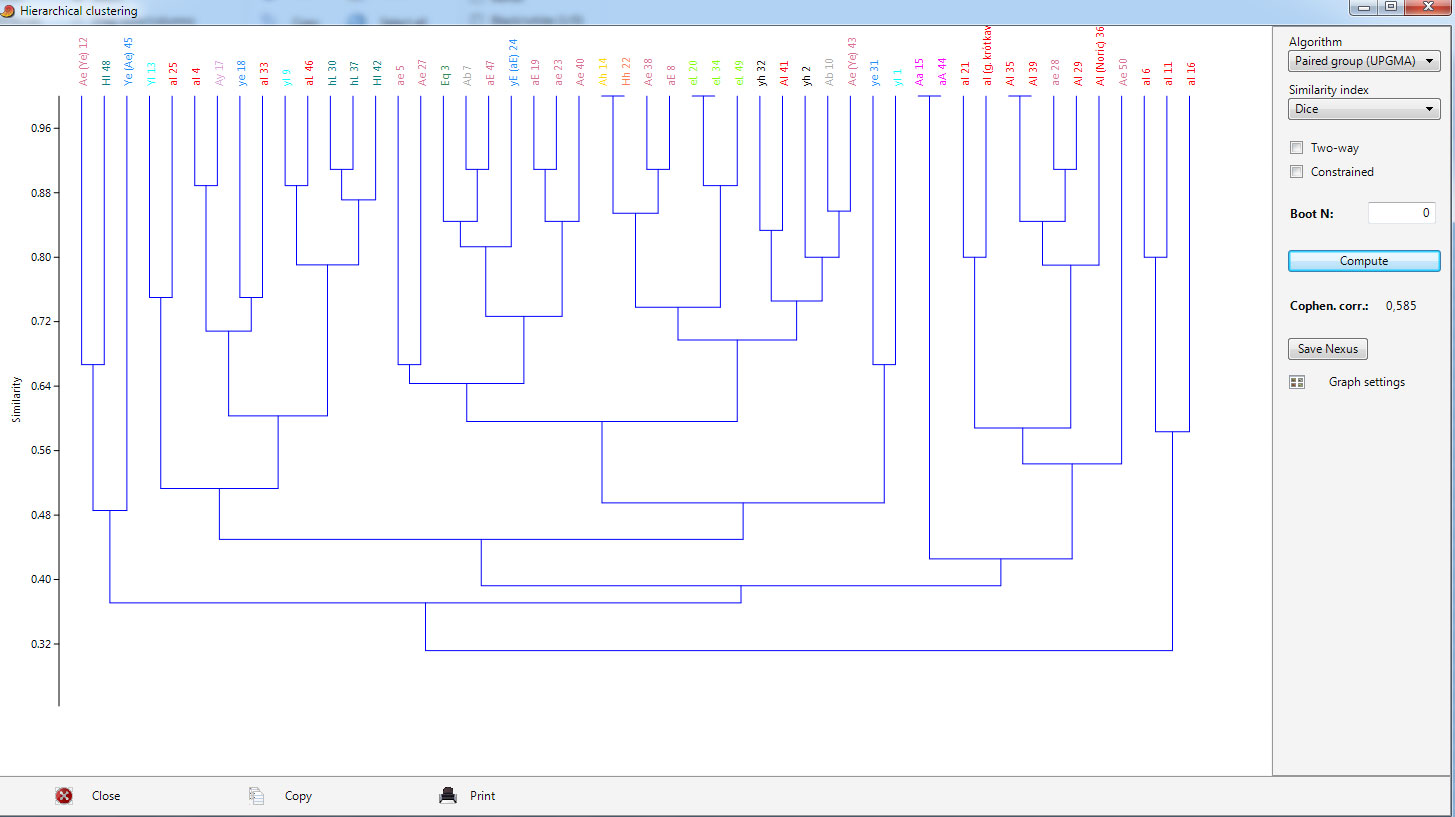
Jedziemy dalej. Ktoś może wysunąć zarzut że czemu używamy wskaźników, może wymiary bezwzględne byłyby lepsze? Czemu nie, wstawiłem do programu zamiast wskaźników wymiary: długości i szerokości głowy, wysokości twarzy górnej i całkowitej, szerokości twarzy, oraz wysokości i szerokości nosa. Cechy opisowe zostały takie jak przedtem. Trzeba zaznaczyć że typy te były wyróżniane przy pomocy wskaźników, a nie wymiarów, jednak wystąpiło mnóstwo zgodności...
Para Ab 7 (zdjęcie) i Yh 2 (zdjęcie) która się będzie powtarzać w następnych dendrogramach nawiązuje do siebie bardzo dużymi wymiarami głowy, wysokim wzrostem i tym co po angielsku ładnie się nazywa "robustness", oraz zapewne podobieństwem B do Y we wskaźnikach, jak wspominałem poprzednio. Ogólnie są to "outsiderzy" w tej badanej próbie.
Użyto metody nieważonych średnich połączeń (UPGMA) w oparciu o miarę podobieństwa Cosine.

Teraz użyjemy tylko wskaźników (główny, twarzowy całkowity, górnotwarzowy, wysokości nosa, nosowy, jarzmowo-ciemieniowy i wysokosci gónej wargi) i cech opisowych. Obaj AB wylądowali w jednej grupie "kromanionoidalnej" znowu. Ogólnei układ bardziej prawidłowy jak wyżej.
Użyto metody nieważonych średnich połączeń (UPGMA) w oparciu o miarę podobieństwa Gower.

Na koniec łączymy wszystko co było przedtem (wskaźniki, wymiary, cechy opisowe). Wyniki są znowu bardzo prawidłowe.
al 6 łączący się z Hl 48 poza kolorem oczu niewiele się od nich różnią, stąd parowanie (wspólny element L). Osobnik al 11 w grupie "armenoidalnej" ma dość ciemną pigmentację skóry i włosów (ale jasne oczy), wąski nos (ale o profilu falistym) i najwyższy w całej badanej próbie wskaźnik wysokości nosa, dodatkowo jest niski, stąd korelacja wymuszona przez program.
Użyto metody nieważonych średnich połączeń (UPGMA) w oparciu o miarę podobieństwa Correlation (Pearson's r).

Dla porównania użyto metody łączenia sąsiada (Neighbour Joining) w oparciu o miarę podobieństwa euklidesową. Dane te same. Uwagi co d korelacji al 11 i al 6 z Hl jak wyżej
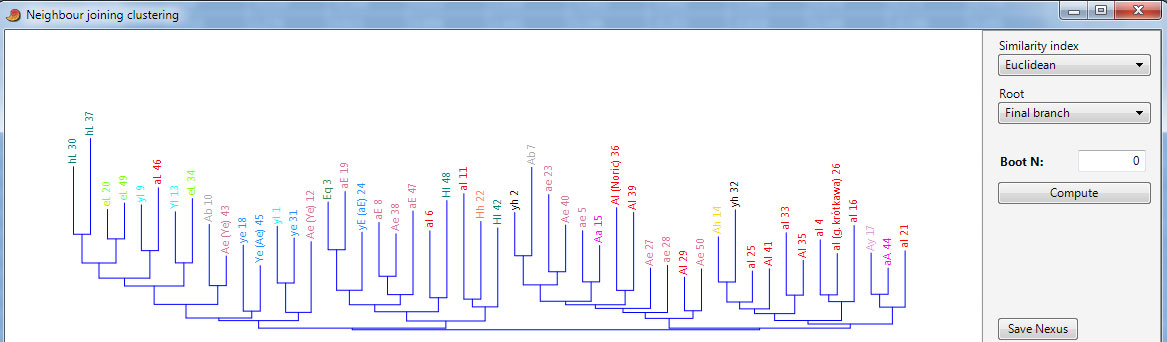
Podsumowując wielocechowa analiza statystyczna zarówno przy grupowaniu hierarchicznym jak i grupowaniu metodą najbliższego sąsiada dzieli badaną próbę 50 osób na pary, trójki, często też większe grupy (podgałęzie) które są frakcjami, typami, względnie pokrewnymi grupami typów (połączonych wspólnym elementem, np YE i YL - tym samym podobne w wielu cechach). Będące zawsze w mniejszości pary "nietypowe" (np. al11 w grupie armenoidalnej) są połączone w logiczny sposób (podobieństwo części cech), ale akurat w ich przypadku program nie "wiedział" że np. jasne oczy ważą więcej w hierarchii cech używanych do określania typologicznego.
Zauważmy też jak program jest generalnie czuły na różnice we wskaźniku głównym. Jeśli jakieś typy o różnych zakresach wskaźnika głowy są zgrupowane w jednej grupie, to musi dodatkowo łączyć je więcej ważnych cech, jak jasne oczy, wąska twarz i nos oraz dość wysoki wzrost we frakcji nordycznej Al grupującej się przeważnie z typem AE. Zwraca uwagę że jedyny nietypowy al 26 o głowie w zakresie pośrednim, jest przez program grupowany zawsze z innymi al we frakcji centralnej (raz tylko na pierwszym dendorgramie w grupie wystąpił yl, ale i tak przeważał w niej typ subnordyczny). Choć jego wzrost i dość ciemne włosy mogły by sugerować grupowanie np. z AE.
Wprawdzie pierwszy dendrogram z najmniejszą ilością cech wydzielił typy najdokładniej ale też najłatwiej go skrytykować jako operujący subiektywnym zestawem cech. Dlatego stopniowo rozszerzałem ilość cech i mimo "strat" nadal większość osobników jest grupowana prawidłowo. Jako że nie ma hierarchii cech, program grupuje według największego podobieństwa w szeroko pojętym fenotypie, mimo to, patrząc na ostatni dendorgram, tylko para Al 11 i HH 22 jest zupełnie niespokrewniona wg zasad typologii morfologiczno-porównawczej. Typ AB jak wspominałem wcześniej jest tu traktowany tak samo jak pochodne Y pod względem wskaźników.
Co ciekawe, na konferencji z 1952 [Przegląd Antropologiczny, t. 19, 1953] omawiającej metody taksonomiczne różnych "szkół" z polskiej i zagranicznej antropologii fizycznej, wspominano już o wielocechowej analizie statystycznej w ujęciu Mahalanobisa, ale zostało to skrytykowane przez innych antropologów jako metoda przematematyzowana, wymagająca kolosalnego nakładu pracy... Nie ma się co dziwić, bez komputerów stworzenie powyższych dendrogramów byłoby katorżniczą pracą i zajęło by wiele tygodni:)
Dlatego nie ma się co dziwić że używano wtedy prostszych metod statystycznych (Czekanowski, Wanke, Perkal), które słusznie krytykowali antropolodzy z kierunku morfologiczno-porównawczego jako mało dokładne lub wręcz dające błędne wyniki. Lecz akurat Perkal zwrócił uwagę na niedoceniony wtedy fakt że trzeba dokonywać standaryzacji cech przy określaniu statystycznym (teraz wydaje się to oczywiste), oraz że może warto zamiast wskaźników używać wymiarów (ustandaryzowanych) - wziąłem to pod uwagę i ma to sens rzeczywiście. Używał też do grupowania tzw. dendrytów będących uproszczonym odpowiednikiem dendrogramu. Wszystko robił bez komputera, więc należy się szacunek.
Należy podkreślić że podział dotyczy cech fenotypowych, więc wydzielone typy są techicznie rzecz ujmując fenotypami i tak nalezy je traktować. Nie wnikam tu w ich genetyczne powinowactwo.
BIBLIOGRAFIA
- Henzel T., Michalski I.,Podstawy klasyfikacji człowieka w ujęciu Tadeusza Henzla i Ireneusza Michalskiego (oraz dyskusja do artykułu) [w:] Przegląd Antropologiczny, t. 21, z. 1-2, 1955
- Omówienie wszystkich metod taksonomicznych antropologii (różni autorzy) [w:] Przegląd Antropologiczny, t. 19, 1953
- Użyłem programu statystycznego do dendrogramów - PAST (PAleontological STatistics) 3.11 oraz Open Office Calc do innych obliczeń. Dodatkowo standaryzację wykonywałem programem MaCzek.
- http://folk.uio.no/ohammer/past/multivar.html - omówienie metod użytych w dendrogramach generowanych przez program PAST
")


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}